




"Which company offers the most advanced data centre routing and networking technology?"
Data Centre Network Interconnection Technology
Today, data centre (IDC) networks are returning to their original simplicity and becoming independent from business operations. Simplicity and reliability are now the primary requirements. Data centres only need to offer simple and reliable layer 3 underlay networking, while the layer 2 overlay network relies more on host-side software or smart network cards.
So, how do you choose a suitable routing protocol for the layer 3 networking of the data centre? This article focuses on the large data centre scenario and aims to provide a definitive answer.
IDC Network Architecture Evolution
Traditional architecture of data centre networks
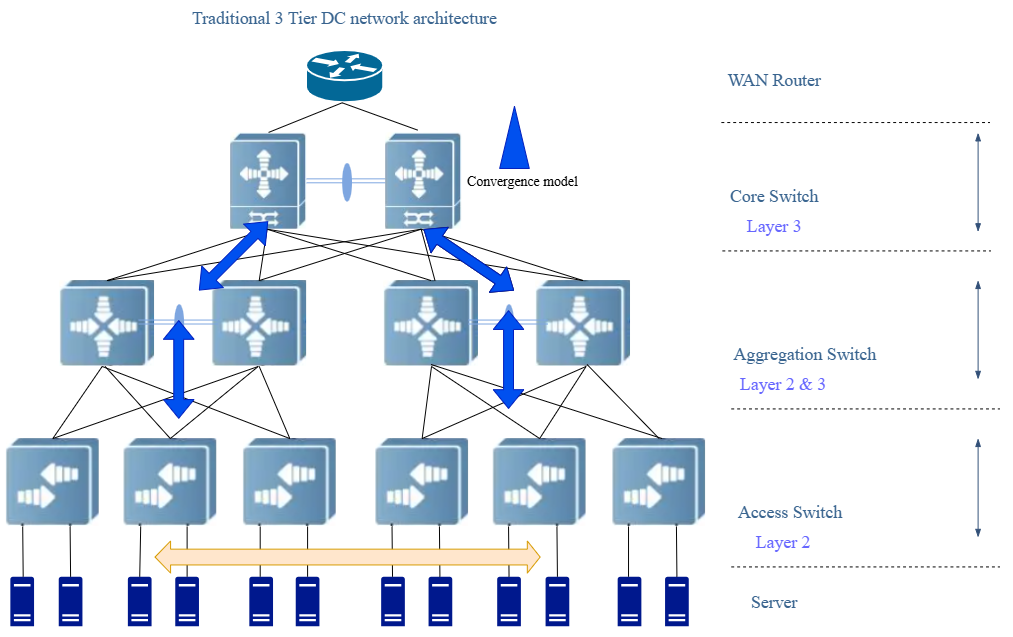
Figure 1 depicts the network architecture of a conventional data centre.
● Traditional IDCs primarily offer services that allow external access to data centres.
In recent years, the deployment of cloud computing, big data, and other business technologies has led to the widespread use of distributed computing, distributed storage, and other technologies within IDCs. From a networking standpoint, there has been a significant increase in east-west traffic within IDCs, leading to a shift from the traditional 80/20 traffic model to a model dominated by east-west traffic.
Hence, the traditional network architecture started to exhibit numerous drawbacks and began to fail.
Fabric network architecture
Fabric is a familiar concept for network engineers. A frame-type switch based on the CLOS architecture relies on fabric (switchboard) as the forwarding bridge for line cards within the device as shown below in Figure 2.

The fabric networking architecture widely used in contemporary data centres closely resembles the CLOS switch.
● Line card: This serves as both an input and output source, aggregating the traffic of all servers. It can be considered equivalent to the top-of-rack switch (TOR) of an IDC.
Folding Figure 2 in half reveals the Leaf-Spine network architecture, which is widely used in data centres today.
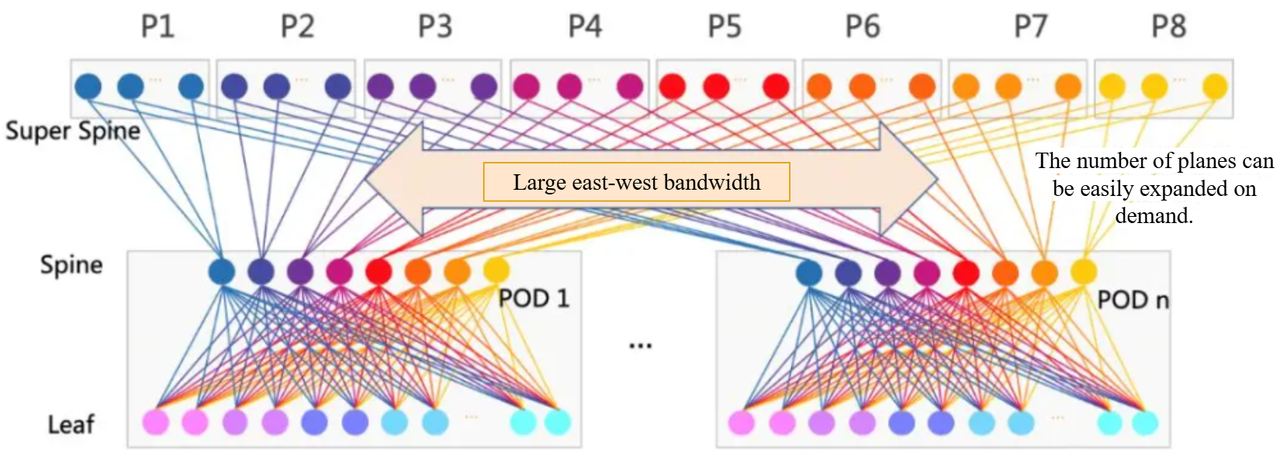
In an IDC, a Leaf-Spine network is formed, based on the smallest delivery unit, known as the POD (Point Of Delivery). To enhance the scalability of this network architecture, a layer is typically added on top of the POD to horizontally connect the PODs of different data centres and expand the scale of the entire data centre cluster.
Leaf-Spine architecture is highly praised for its powerful scale-out capability, extremely high reliability, and excellent maintainability. Well-known global Internet giants all use this networking architecture.
What routing protocol does the Fabric network architecture use?
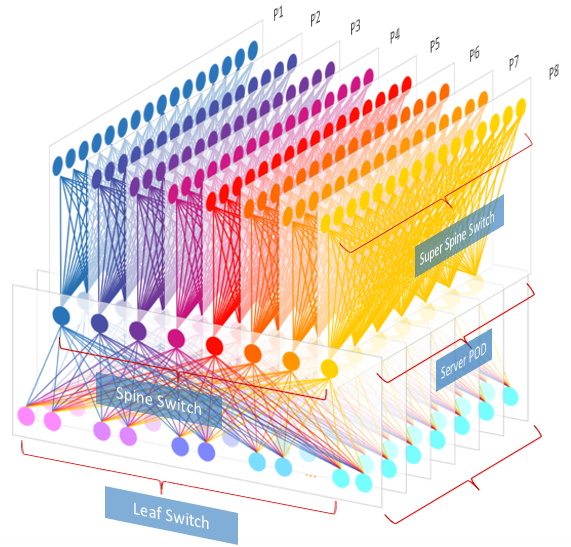
Facebook opened its data centre network design in 2014, evolving from F4 to F16 while maintaining the same basic architecture as Figure 4, using a typical Fabric network. The question arises: which routing protocol is more suitable for Fabric network architecture.
In RFC 7938 "Use of BGP for Routing in Large Scale Data Centres," the author proposes using Border Gateway Protocol (BGP) as the unique routing protocol within data centres and provides a detailed analysis. For further details, please refer to the original RFC.
Combining this RFC with the current practices of domestic and foreign Internet companies using BGP networking, let's analyze why BGP is more popular.
Design Principles for Large IDC Network Routing
1. Scalability
Design considerations for routing protocols:
2. Bandwidth and Traffic Model
Design considerations for data centre:
Design considerations for routing protocols:
3. CAPEX Minimization
Design considerations for data centre:
Design considerations for routing protocols:
4. OPEX Minimization
Design considerations for data centre:
Design considerations for routing protocols:
Selecting the appropriate routing protocol for large Internet Data Centre (IDC) networks.
1. "Essential capabilities required by routing protocols"
2. "Existing Routing Protocol Matching."
Let's delve into the extent of compatibility among the current routing protocols.
3. OSPF VS BGP
"The following are Wikipedia's definitions of the OSPF and BGP protocols."
It's important to note that OSPF and BGP are both widely used routing protocols, and neither is inherently superior or inferior. In the context of large or super-large data centres, it's crucial to analyze the applicability of these two routing protocols.
|
Protocol Type
Comparison Item
|
OSPF
|
BGP
|
|
Routing Algorithm
|
Dijkstra algorithm
|
Best path algorithm
|
|
Algorithm Type
|
Link Status
|
Distance Vector
|
|
Bearer Protocol
|
IP
|
TCP has a retransmission mechanism to ensure the reliability of protocol data.
|
|
Requirement 1: Large-scale networking
|
Applicability: ★★★ In theory, there is no limit on the number of hops, and it can support large-scale routing networks. However, 0SPF needs to regularly synchronize link status information across the entire network. For ultra-large-scale data centres, the link status information database is too large, and the performance consumption of network equipment during calculation is high. Simultaneously, network fluctuations have a significant impact on the area.
|
Applicability: ★★★★★ Only transmits the calculated optimal routing information. Applicable to large or super-large data centres. Mature practices have been implemented in super-large campuses.
|
|
Requirement 2: Simple
|
Applicability: ★★★ Simple deployment, moderate operation, and maintenance
|
Applicability: ★★★★ Easy to deploy and maintain.
|
|
Requirement 2: Please ensures that a single type of routing coordinator is deployed in the IDC. This will streamline our operations and ensure consistency in our routing processes.
|
Applicability: ★★★★ Satisfies IDC's internal deployment of the OSPF single routing protocol and offers rich software support on servers.
|
Applicability: ★★★★ Satisfy
|
|
Requirement 4: Reduce failure domains
|
Applicability: ★★ Link status information must be synchronized within the domain, and all failures must be updated synchronously.
|
IDC can deploy only the BGP single routing protocol internally, and there is also software support for external autonomous systems to use BGP interconnection on the server.
|
|
Requirement 5: Load balancing
|
Applicability: ★★★★ Plan the cost value and form ECMP when there are multiple links. When a link fails, it is necessary to synchronize the calculation of devices in the domain.
|
Applicability: ★★★★ BGP locally propagates only the calculated best path. When the network changes, only incremental information is transmitted.
|
|
Requirement 3: Deploy a single type of routing protocol in IDC
|
Applicability: ★★★★ Satisfies the requirement that only the OSPF single routing protocol can be deployed within the IDC, and it also has extensive software support on the server.
|
Applicability: ★★★★★ Rules and regulations. After determining the number of hops and AS, ECMP can be formed when there are multiple links. When a link fails, the next hop corresponding to the link will be removed from the ECMP group.
|
|
Requirement 6: Flexible control
|
Applicability: ★★★ The use of Area and ISA types effectively controls route propagation, as this process can be quite complex.
|
Applicability: ★★★★ Utilize a range of routing principles to effectively filter and regulate the transmission and reception of routes.
|
|
Requirement 7: Fast Convergence
|
Applicability: ★★★ When the number of routes is small, millisecond-level convergence can be achieved through BFD linkage. The notification is link status information. However, when the routing domain is large, the computational consumption increases, resulting in slow convergence.
|
Applicability: ★★★★ When there are only a few routes, millisecond-level convergence can be achieved using BFD linkage. The announced routes are locally calculated, so performance won't be significantly affected even in large routing domains. Additionally, BGP has AS-based fast-switching technology.
|
Based on our analysis of the table and industry practices, we recommend using the OSPF protocol for small and medium-sized data centres with a small number of network devices in the routing domain. For large or super-large data centres, it's more suitable to deploy the BGP routing protocol.
Summary

Related Blogs:
Exploration of Data Center Automated Operation and Maintenance Technology: Zero Configuration of Switches
Technology Feast | How to De-Stack Data Center Network Architecture
Technology Feast | A Brief Discussion on 100G Optical Modules in Data Centers
Research on the Application of Equal Cost Multi-Path (ECMP) Technology in Data Center Networks
Technology Feast | How to build a lossless network for RDMA
Technology Feast | Distributed VXLAN Implementation Solution Based on EVPN
Exploration of Data Center Automated Operation and Maintenance Technology: NETCONF
Technical Feast | A Brief Analysis of MMU Waterline Settings in RDMA Network
Technology Feast | Internet Data Center Network 25G Network Architecture Design
Technology Feast | The "Giant Sword" of Data Center Network Operation and Maintenance
Featured blogs
- CXL 3.0: Solving New Memory Problems in Data Centres (Part 2)
- Ruijie RALB Technology: Revolutionizing Data Center Network Congestion with Advanced Load Balancing
- Multi-Tenant Isolation Technology in AIGC Networks—Data Security and Performance Stability
- Multi-dimensional Comparison and Analysis of AIGC Network Card Dual Uplink Technical Architecture
- A Brief Discussion on the Technical Advantages of the LPO Module in the AIGC Computing Power Network






